Lignes directrices¶
Les lignes directrices du PGD de Biblissima+ définissent des exigences minimales à respecter dans la gestion des données produites ou collectées durant le projet.
1¶
Le PGD de Biblissima+ est centré sur le périmètre de données lié à l’infrastructure numérique gérée par l’équipe technique du projet appéle également « équipe portail ».
Ce périmètre (P1) comprend le portail web, le cluster de données sous-jacent, les référentiels d’autorité assurant la mise en interopérabilité des ressources ainsi que les outils de traitement mis en œuvre.
2¶
Les briques de l’infrastructure produites par les équipes partenaires (périmètre P2) ou les opérations financées via les appels à projet annuels (périmètre P3) font l’objet de PGDs particuliers, rédigés et mis à jour par les responsables scientifiques et techniques de ces contributions.
Le livre blanc1 de Biblissima+ comprend une grand variété de contributions. À titre d’illustration, on peut mentionner les types de contributions suivants :
- les catalogues de notices,
- les extractions de bases de données scientifiques,
- lescorpus spécialisés,
- les éditions de sources,
- les thésaurus,
- les listes d’autorité (noms de personnes, de lieux, identifiants),
- des vocabulaires contrôlés
- ainsi que les codes sources de logiciels ou scripts ou modèles informatiques (3D, intelligence artificielle, apprentissage machine) associés aux outils, méthodes et protocoles proposés.
3¶
Les jeux de données du périmètre P1 sont placés sous la responsabilité du bureau exécutif et de l'établissement porteur Campus Condorcet.
Les jeux de données des périmètres P2 et P3, sont quant à eux sous la responsabilité des équipes partenaires produisant ou collectant les données et les codes sources et de leurs établissements tutelles.
4¶
Les PGDs particuliers sont rédigés et mis à jour par les responsables scientifiques des livrables et sont placés sour la responsabilité des établissements tutelles des équipes scientifiques impliquées. Il doivent respecter les politiques de Science ouverte de ces tutelles quand elles existent. Pour rédiger ces documents il est recommandé d’utiliser un modèle de PGD permettant l’export des données dans le format normalisé défini par l’organisation internationale RDA. Deux outils sont disponibles à ce jour : le « modèle structuré » de plan de gestion de données de la plateforme DMP OpiDor2 (en français) et l’outil en ligne ARGOS, proposé par l’infrastructure européenne OpenAIRE3 (en anglais)4.
5¶
Le PGD principal aussi bien que les PGDs particuliers s’inscrivent dans une démarche de Science ouverte conforme à la politique générale de l’ANR en la matière et au plan national porté par le MESRI5. Les données produites doivent être structurées et rendues exploitables en fonction des principes FAIR (faciles à trouver, accessibles, interopérables, réutilisables).
Le PGD principal et les PGDs particuliers définissent explicitement la manière dont ces données seront préservées et partagées. Ils indiquent a minima : l’entrepôt qui sera utilisé pour le dépôt, le niveau d’agrégation, les conditions d’accès et les licences de réutilisation.
6¶
Les données sont mises à disposition de la manière la plus ouverte possible. Lorsqu’il n’est pas possible de diffuser les données sous une licence ouverte, ou lorsque la diffusion ouverte est soumise à un embargo, les raisons en sont expliquées dans le PGD (droits de propriété intellectuelle, présence de données sensibles, etc.)
7¶
Tout jeu de données ayant vocation à être intégré dans le portail Biblissima+ doit faire l’objet d’un dépôt documenté dans un entrepôt fournissant un identifiant pérenne (par exemple un DOI).
Le dépôt contient a minima 3 fichiers au format .txtou .md6 :
- un fichier README7 expliquant notamment son organisation (arborescence des fichiers) et le dictionnaire des données ;
- un fichier LICENCE donnant la licence de diffusion, précisant les conditions de réutilisation en général et en particulier au sein du portail Biblissima+ ;
- un fichier AUTHORS contenant la liste des auteurs et des contributeurs éventuels.
Le diagramme ci-dessous illustre les principales étapes du processus et les responsabilités associées. Les étapes liées aux périmètres P2 et P3 sont sous la responsabilité des équipes qui définissent, extraient et organisent leur « jeu de données ». À titre d’exemple on peut citer : une collection de notices issues d’un catalogue, d’une base de données scientifiques, d’un corpus TEI ou d’un référentiel.
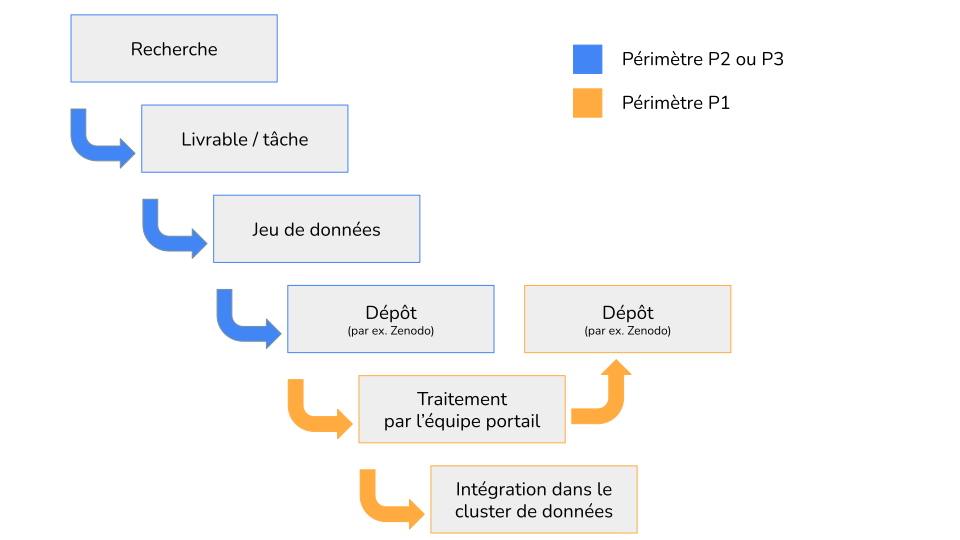
Chaque équipe peut définir le type d'accès qu'elle réserve à ses jeux de données :
- Accès limité uniquement à l’équipe portail ;
- Accès limité uniquement aux équipes partenaires de Biblissima+ ;
- Accès ouvert à tout le monde (en spécifiant les types de licence pour la réutilisation des données) ;
Quel que soit le type d'accès privilégié, chaque équipe devra également préciser si elle est ou non d’accord pour que l’équipe portail mette à disposition les fichiers enrichis des jeux pour de données versés dans le portail Biblissima+. Ces conditions de mise à disposition – limitée à l’équipe partenaire ou à l’ensemble des équipes de partenaires de Biblissima+ ou libre accès pour tous… – sont à indiquer explicitement dans les fichier fichiers README et LICENCE à joindre au dépôt.
L’équipe Portail récupère le jeu de données à traiter depuis le dépôt et procède aux normalisations, alignements et enrichissements décrits plus bas.
8¶
Les clusters jouent également un rôle clé pour l’accompagnement et le suivi de la gestion des données. La préparation des agrégations à déposer pour le partage et l’archivage peut bénéficier des réflexions collectives et de mise en commun d’outils ou de workflows éprouvés. Des espaces serveurs partagés fondés sur l’outil « Sharedocs » de l’infrastructure de recherche Huma-Num seront mis à la disposition des clusters pour préparer, documenter et tester les jeux de données préalablement à leur dépôt.
Les droits d’accès seront gérés de manière autonome par les responsables de cluster ou les référents données.
L’équipe portail peut être sollicitée pour prodiguer des conseils ou vérifier que toutes les informations utiles pour l’intégration du jeu de données au sein du portail après dépôt sont présentes et valides.
9¶
Le choix de l’entrepôt pour l’archivage et le partage est libre.
En ce qui concerne les codes sources, plusieurs stratégies utilisant les outils de gestion de code open source communément utilisés (Gitlab, Github) en combinaison avec la plateforme d’archivage Software Heritage sont définies dans la partie du PGD consacrée au périmètre P1. La stratégie de documentation et de diffusion du jeu de données peut en effet varier selon l’importance scientifique ou patrimoniale des contribution ou le niveau de visibilité souahaitée.
Les PGDs particuliers des codes source produits dans les Périmètres P2 et P3 peuvent s’inspirer de ces stratégies ou s’y référer si cela paraît utile aux responsables scientifiques et techniques.
10¶
Zenodo est l’entrepôt principal recommandé pour la diffusion et l’archivage des sets de données.
Il est conseillé de créer un dépôt pour chaque version majeure du produit de recherche. Les jeux de données devront être déposés dans l’une des communautés Zenodo créée pour chaque cluster à cet effet. La curation de la communauté principale https://zenodo.org/communities/biblissima/ est assurée par l’équipe portail. Si les équipes partenaires disposent d’une communauté Zenodo en propre, elles peuvent bien entendu y associer ces dépôts.
11¶
En ce qui concerne les dépôts dans d’autres plateformes, ceux-ci sont signalés dans un inventaire géré par le cluster (par exemple sur un cloud collaboratif Sharedocs de l’infrastructure de recherche Huma-Num mis à disposition du cluster).
12¶
Lors des journées annuelles des clusters, un point est fait sur les dépôts. Il est suggéré d’organiser des sessions collectives à cette occasion pour tester en groupe la fiabilité des données déposées ou contrôler collectivement la clarté et l’intelligibilité des métadonnées, et de la documentation.
-
Document rédigé par les équipes partenaires qui présente en détail l’infrastructure numérique envisagée (téléchargeable depuis la page : https://projet.biblissima.fr/fr/projet/presentation) ↩
-
Cf. https://www.inist.fr/services/accompagner/webinaire/outil-dmp-opidor-modele-de-plan-de-gestion-de-donnees-structure/ ↩
-
Le format commun est disponible sur GitHub : https://github.com/RDA-DMP-Common/RDA-DMP-Common-Standard ↩
-
Voir https://www.enseignementsup-recherche.gouv.fr/fr/le-plan-national-pour-la-science-ouverte-les-resultats-de-la-recherche-scientifique-ouverts-tous-49241 ↩
-
Ces recommandations s’inspirent des règles de dépôts des logiciels et codes sources mis en place dans la collaboration Archive HAL/Archive Software Heritage. Voir la page de documentation https://doc.archives-ouvertes.fr/deposer/deposer-le-code-source/ à ce propos. ↩
-
Voir https://www.ionos.fr/digitalguide/sites-internet/developpement-web/fichier-readme/ ↩